
Production ready service for face blurring with Go and React. Part 1: System design
Articles in this series
Let's design and build a service for blurring faces like this one, with Go and React, using a model provided by Tensorflow. The task of queuing something is a typical one for system design, so it makes sense to cover this topic in details.
The service should be production ready, with ability to scale. This is going to be a good exercise that will cover a lot of things, including, but not limited to queue processing, websockets, AI, observability, logging, etc.
Before committing to the system design itself, let's outline the acceptance criteria and main features.
- The service should support uploading photos to a bucket and blurring human faces if detected
- The list of uploaded photos must be stored on the backend for a user and shown in the UI
- Processed photos must be stored next to the original ones
- Shortly after the photo is processed, it must be sent back to the front-end using websockets
- The deployment should be containerised, not using lambdas.
- The service should support horizontal scaling of each of the components, in order to potentially handle millions of requests
- There must be metrics exported to analyze
- The average task duration
- Amount of tasks executed per a day
- Amount of failed tasks
On a very high level the system is represented as a dashboard talking to the API backend using REST.
However, as we need to accommodate the criteria listed above, we can extend the design by introducing smaller components:
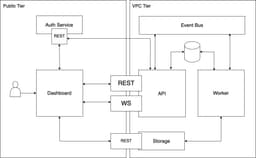
Here,
- The application has two tiers: Public tier (untrusted) and VPC tier (trusted).
- The process of finding and blurring faces may take certain amount of time, therefore cannot be done synchronously. It must be asynchronous, which means there must be a job created and put into a process queue. For that a separate service is needed - the Worker service.
- The API service provides REST endpoints for obtaining the list of uploaded images. Since the jobs are executed asynchronously, there should be a way to communicate the status update back to the client in real time. For that, Websockets could be utilised.
- The Dashboard is a web application where all the uploaded images are displayed. It also allows uploading more images.
- The communication between the Public and VPC tiers must be secured. There are many ways to achieve this, but one of the options could be JWT and OAuth0. In order to do that, we need a dedicated Auth service.
- The files obviously may not be stored in the container file system. An external storage is needed.
- The Database is used to store a list of uploaded files and the job queue. Having the database shared between several microservices is okay here, because both services belong to one domain and share the complete set of data.
- The Event bus allows the API service and the Worker service communicate with each other.
For a cloud native application scaling is an important topic. In order for the system to be able to handle millions of requests per a second, it must:
- move all heavy jobs to the background and thus delay the execution and
- effectively scale horizontally, so the work load can be distributed and done faster.
So.
- All Public tier communications between the services are a subject to regular Internet network lag.
- The VPC tier communications are covered by the Cloud provider using low latency network, and we have only limited influence on that.
- The Dashboard runs on the client side and obviously doesn't need to be scaled.
- The Auth service, should a third party service be chosen, is scaled by the infrastructure of the vendor.
- The Storage is managed by the Cloud provider, and it's scalability is not our primary concern.
- The event bus, if not hosted on premises, doesn't require any manual measures for scaling.
- The database can be scaled in two ways:
- adding read replicas,
- introducing sharding, for example, by the user id.
- The Worker service we scale manually now, and later autoscaling with tools like Keda may be enabled. Multiple replicas can be created, but a there is a question: "How to balance the work load between them?"
- We can introduce the partition key, and distribute the load based on its value. It can be any value that
works the best.
- The main idea here is for every replica to know exactly which range of the messages it's responsible for.
- Each replica knows nothing about the other replicas, and unaware of their existence (unless we have a cluster, which would be over-engineering for this case).
- Another option would be to have a load balancer - an external entity that will decide which replica takes the next job.
- The round-robin load distribution then may be used, as well as any other smart algorithm that picks the right worker for the job.
- With or without the load balancer, we should avoid overheating replicas in cases when certain partition keys are updated way more frequently than the other.
- In our simple case we can start with two replicas, so the partition key can be a serial integer and one node would serve even keys, while the other - odd keys.
- Each replica can run threads to parallelize the process even further. Typically, the amount of threads equals to the amount of CPU cores available.
- We can introduce the partition key, and distribute the load based on its value. It can be any value that
works the best.
- The API service we must scale by setting the amount of replicas for the deployment. The Kubernetes internal load balancer will take care of balancing traffic between the replicas.
Let's dig one level deeper and see what's inside every component of the system.
First let's identify the list of entities and how they relate to each other.
- The
Imageentity holds information about images uploaded by users. - The
Userentity holds information about users. - The
ProcessingQueueentity represents an entry of the processing queue. TheImageentity itself can't play this role, because one image could be processed multiple times if necessary.
All datetime-s must be stored as TIMESTAMP WITH TIMEZONE and in the UTC timezone (no timezone essentially) to remove any possible ambiguity. If the backend wants to modify datetime-s internally, it must first convert the datetime-s to the business entity timezone and then back to UTC for saving.
The Dashboard is quite a minimalistic SPA that provides:
- A single view for a user to interact with - the home page listing all images ever uploaded, with pagination.
- A widget for the file upload, using either drag-n-drop or choosing from the file picker.
- An authentication widget that will allow users to sign-in.

Anonymous access isn't allowed, that's why until the user signs-in the image uploading is not possible.
As soon as an image is uploaded, the processing starts. However, it won't happen immediately. The Dashboard must keep the websocket connection open to get notified when the backend is done processing an image. When that happens, the Dashboard reloads the image with faces blurred.
The API service basically implements the backend-for-frontend pattern. It implements both REST and WebSocket transport. Going WebSockets-only is technically possible, but it adds additional overhead and stretching points in the Dashboard logic, that we probably don't want to have. When a Dashboard wants to request some data, it makes use of REST endpoints, and the Dashboard also listens to the async event coming from the server.
Ideally, both REST and WebSocket response body should have equivalent structure, to make the transport layer easily interchangeable without needs for introducing drastic logic alterations.
When it comes to REST, there are two ways to have it.
- Classic REST with different verbs and structure. This approach is recommended when the API is publicly available.
- RPC-style endpoints. In this case only POST is used, and each endpoint bears the name of the function it executes, e.g.
/book/createwill execute Books.Create() method. Many fullstack frameworks benefit from this approach, as POST is rather reliable and don't suffer from limitations of other verbs such as GET or DELETE.
Since we don't build public API, the second way is preferred.
Let's now cover the API contract.
- The content type of both requests and responses shall be
application/json. - All datetime-s coming from or going to REST and WebSockets must be in the ISO 8601 format and be in the UTC timezone (no timezone essentially). This will help to remove ambiguity and give the Dashboard an option to choose what timezone to display to a user: the local browser timezone, the business entity timezone or something else.
- Every time a call happens, a random UUID is chosen by the server. This ID is returned among the response headers, and later can be used as a tracking ID to search for log entries associated with this call:
X-Operation-Id: 93ccfa49-4780-4081-8232-8e67c50a5358 - The API should support versioning. The version number will be included into the path as the leading element.
So, we need to support the following endpoints:
👉 POST /v1/upload/url/get gets a new signed URL for file upload.
// request:{}// response:{version: "v1",url: "https://our-storage/uploadhere"}
✅ POST /v1/image/submit creates a new image and puts it to the blurring queue.
// request:{image: {url: "https://our-storage/path/to/image"}}// response:{version: "v1",image: {id: "ff6d69df-fcdf-4f79-a33c-ece142fc9877",url: "https://our-storage/path/to/image",is_processed: false,is_failed: false,created_at: "2025-12-25T12:34:56.123456Z",updated_at: "2030-02-28T11:59:59.000001Z"}}
Here, the processed flag indicates that the image is still being processed.
✅ POST /v1/image/list list all images for the current user.
// request:{page_navigation: {page_size: 30,page_number: 1}}// response:{version: "v1",images: [{id: "ff6d69df-fcdf-4f79-a33c-ece142fc9877",url: "https://our-storage/path/to/image",is_processed: false,is_failed: false,created_at: "2025-12-25T12:34:56.123456Z",updated_at: "2030-02-28T11:59:59.000001Z"},{id: "904fcfdd-6908-4078-91a5-cdcc18d9f239",url: "https://our-storage/path/to/image-2",is_processed: true,is_failed: false,created_at: "2025-12-25T12:34:56.123456Z",updated_at: "2025-12-31T23:59:59.999999Z"}],page_navigation: {page_size: 30,page_number: 1,page_count: 1,total: 2}}
The page navigation is calculated on the server and sent over to the client for rendering the pagenav controls.
The ordering of the items should be stable, that's why by default order by created_at DESC is applied.
In case of an error, the response body should be of the following format:
{error: "Something terrible has happened"}
The HTTP code should be set accordingly: for internal errors it is 500, if something isn't found - 404 and so on.
The operation id will then help to identify the exact reason for the failure.
The WebSocket will be used to receive updates from the server upon queue changes, asynchronously. It makes sense then
to align the structure of the message with the /v1/image/list endpoint:
{version: "v1",images: [{id: "ff6d69df-fcdf-4f79-a33c-ece142fc9877",url: "https://our-storage/path/to/image",is_processed: true,is_failed: false,created_at: "2025-12-25T12:34:56.123456Z",updated_at: "2030-02-28T11:59:59.000001Z"}]}
Having an array of images will technically allow receiving bulk updates, should the backend decide to group several images into one message.
Event bus is used mainly for two purposes: 1) data propagation between microservices inside a cloud native application, 2) to perform message multicasting.
Despite the fact that direct RPC-like pod-to-pod communication via a load balancer is definitely an option, it can quickly turn into mess when the system grows. Also, it's hard to multicast messages, when multiple pods should receive a message: the load balancer simply won't allow that. In that case every party has to have an exact list of recipients.
An Event bus could be a solution. It is needed to enable communications between the API and the Worker.
In our system there will only be two types of messages:
- Notify about the queue change: there are new jobs to do.
- Notify about the queue change: a job was completed or failed.
Then, services can subscribe to those messages:
- The worker will re-fetch the queue and put new jobs into work.
- The API will send an update through WebSockets. Upd: alternatively, a more modern technology - WebRTC can be considered. Also, since the messages are coming from the server, and full-duplex isn't needed, Server-Sent events (SSE) can be used as a cheap-to-build alternative option.
When it comes to storing bulk data, there are two good candidates:
- a network filesystem with a mounted partition, or
- a file storage.
Since all files are unrelated and processed separately, and also because an ability to have external and granular access to each individual file is needed, the Storage seems like a better choice.
Before creating an image entry, the image itself must be uploaded to the Storage, using a signed URL. Then the image entry is created via the API.
The Worker is the heart of this cloud native application. It listens to the job queue for new jobs. As soon as a new job arrives, it will:
- download an image into memory,
- run a Tensorflow model that will find all faces on the image and return the rectangular coordinates,
- blur image parts that are inside the rectangles returned by the model,
- re-upload the new image,
- update the corresponding image entry,
- mark the job queue as completed,
- trigger an event.
Even though it's tempting to use the Event bus as a job queue, it's hardly an acceptable solution. For the job queue we need:
- Order of processing. The event queue doesn't guarantee delivery in the exact same order the messages were produced. Also, duplicate deliveries are possible.
- Random access to a job entry, being able to modify the state of it and potentially append information. This isn't possible with the event queue.
The worker can run multiple threads to process several jobs at once. Concurrency-related issues are not expected to appear, as images are isolated from each other and don't depend on anything external.
All connections in the Public tier must be protected with authentication.
- All connections must run over SSL-protected protocols, such as https:// and wss://
- The connection between the Dashboard and the API service should be protected with authentication using JWT and protocols such as OAuth2.
- The JWT is sent in every request made through REST.
- The JWT is also sent during the initial handshake of the WebSocket connection creation process, and then it is being transmitted at regular intervals, so the server understands the connection is still secure.
- The connection to the Storage can be protected using a CDN (such as Cloudflare), but for simplicity we can keep the access public.
- The application ID passed to the Auth Service is publicly available, however, as long as the tokens are secure and being verified, there is nothing to worry about.
Here is the sequence diagram of the image processing, happy flow.
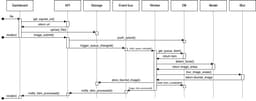
In case of any errors during processing the job fill be marked as failed and that will also be communicated to the Dashboard.
The system must not be running unobserved. Having observability missing is like flying an airplane blind.
Both API and Worker services must expose basic metrics, such as
- CPU and Memory utilization
- Error rate
API specific metrics can include:
- Average REST request duration
- P99 metrics for REST requests
- Specific error rates for Websockets
Worker specific metrics:
- Average job duration
Besides metrics, all logs must be aggregated and be available with back span of at least 2 weeks.
Metrics is an amazing instrument as such, but what makes it really strong is properly defined alerts. Typical alerts can monitor:
- Error rates of both API and Worker services
- Request & job durations above certain threshold
- CPU and Memory consumption
There must be some Dashboard user behavioural metrics as well. Such metrics can include:
- links & buttons click counter and statistics,
- click heatmap,
- screen recording.
This kind of information can give insights on what people really do on the platform, what the struggle with. This could optimise efforts by investing engineering resources into what's really needed, instead of what you assume is needed.
We also should be capturing errors in the Dashboard, as well as spotting potential bottlenecks.
Here is the breakdown of the technologies will be used in the project:
- The Dashboard will be built using React. The choice is well-justified due to the obvious simplicity of the library.
- For visual components the MUI Joy design system will do.
- For networking and related state management, react-query is a good choice.
- It doesn't make a lot of sense to build an Auth service from scratch. An external Auth service such as Auth0 could be used.
- For the Storage we can utilise what our cloud native provider has to offer. It can be an S3 bucket of Amazon, or Storage from GCP. Any AWS-compatible storage will do.
- The API service will be implemented using Golang.
- To implement the Event bus RabbitMQ can be used.
- The Worker will be implemented using Golang. It will call a Tensorflow model, and then call an external binary to blur images.
- The database will be Postgres.
- For the observability of the backend OpenTelemetry can be used, later scrapped by Prometheus and displayed using Grafana.
- Observability on the frontend could be covered by tools such as HotJar or Google Analytics, and for capturing errors and bottlenecks - Sentry.
- Establish API contracts and created a boilerplate for the API service.
- Implement logic of the API service, including communication with the Database using the dependency injection pattern and hexagonal architecture approach.
- Implement the Dashboard, including authentication through Auth0, token check in the API service, file upload and integration with the API service
- Implement Websockets on both FE and BE, integration with the Event bus
- Implement the Worker logic, integration with the Event bus and Tensorflow Serve
- Enable observability, log aggregation and alerting
