
How to use GraphQL Apollo server with Serverless
In the previous article, we have discussed how to use Serverless locally with Webpack and then deploy it to the AWS cloud. Today we talk about how to spin up Apollo GraphQL server inside a lambda function.
GraphQL is a good alternative to REST. It has both upsides and downsides, but useful when dealing with complexly structured, deeply nested rich data. GraphQL allows us to pick only the requested subset of data we need to display client-side in each particular case.
Apollo is one of two widely-used implementations of GraphQL, it includes both server and client, and considered to be a simpler one.
Done with theory.
I am going to use a repository from the previous article as starter code here. Feel free to clone it, or come up with something of your own.
So, in case we decided to proceed with the repository, rename folder ./lambda-app to something more relevant, like ./graphql.app
Also, just to be cool, in ./serverless.yml we could change the function name and the endpoint name from “hello” to “graphql”.
Don’t forget to run npm install inside ./graphql.app, if the repository is freshly-cloned.
The key packages this time would be:
apollo-server-lambda— a binding for theapollo-serverpackage onserverlessgraphql-tag— contains *.graphql file loader for babelgraphql— a peer package forgraphql-tag(“peer package” means thatgraphql-tagis an add-on for graphql and cannot dictate what version of graphql to install)merge-graphql-schemas— allows to compose different type declarations into one structure, so we can properly split the code
cd ./graphql.appnpm install apollo-server-lambda merge-graphql-schemas axiosnpm install graphql-tag graphql --save-dev
GraphQL is a strictly typed language. It means that it needs to know all data types we are going to use. For demo purposes, we are going to create a simple dataset based on famous https://swapi.co/
mkdir -p ./src/graphql/types
We create graphql.app/src/graphql/types/index.js file:
import { mergeTypes } from 'merge-graphql-schemas';import movie from './movie.graphql';import character from './character.graphql';export default mergeTypes([movie, character], { all: true });
Now declare types. There will be two files, one for movies and another — for characters. We will not be digging too deep into the GraphQL syntax, it really goes beyond the scope, but at least we can see how resolvers work, and how to make queries with parameters and without ones.
So,
./graphql.app/src/graphql/types/movie.graphql
type Movie {id: String!title: String!characters: [Character]!}type Query {movies: [Movie]movie(id: String!): Movie!}
There are so-called root types in the declaration, it could be Query, Mutation and several other, each is specific for different situations. So, consider the Query type to be an “entry point” of your GraphQL API.
Square brackets mean that an array of values is expected. Exclamation mark means the attribute is mandatory.
A similar file is for characters:
./graphql.app/src/graphql/types/character.graphql
type Character {id: String!fullName: String!movies: [Movie]!}type Query {character(id: String!): Character!}
Note, that *.graphql files are written in a special kind of language, different from JavaScript. In order to import such kind of files, we need a special loader — a plugin for Babel, which reads the file and translates the declared types into an abstract syntax tree (AST) structures. After that, we combine these structures into one big super-structure with merge-graphql-schemas module.
So let’s enable the loader in ./webpack.config.js file. Find the section with module: {rules: […]} and insert a new rule into the array:
{test: /\.(graphql|gql)$/,exclude: /node_modules/,loader: 'graphql-tag/loader',},
Now that should work.
In GraphQL each complex type can have its own resolver. Typically, a resolver is an asynchronous function which acquires data from a (usually) remote source. This is a key feature of GraphQL: when a certain data subset is requested, only the corresponding resolvers get executed.
Resolvers are mandatory for root types because the GraphQL server needs to know which code to execute in order to process the request. On the contrary, basic types like String, Int, Boolean and so on do not require a resolver.
mkdir -p ./src/graphql/resolvers
Just like before, we create ./graphql.app/src/graphql/resolvers/index.js. Inside the file, we also use merge-graphql-schemas to compose different resolvers into one declaration.
import { mergeResolvers } from 'merge-graphql-schemas';import movieResolver from './movie';import characterResolver from './character';const resolvers = [movieResolver, characterResolver];export default mergeResolvers(resolvers);
./graphql.app/src/graphql/resolvers/movie.js
export default {Query: {movies: async (source, args, { dataSources }, state) => {return dataSources.movieSource(null);},movie: async (source, args, { dataSources }, state) => {// by using "args" argument we can get access// to query argumentsconst { id } = args;const result = dataSources.movieSource([id]);if (result && result[0]) {return result[0];}return null;},},Movie: {characters: async (source, args, { dataSources }) => {console.dir('Executing Movie.characters resolver');return dataSources.characterSource(source.characters);},},};
A resolver function receives four arguments:
source— an object that contains values from the parent resolver. In case we would like to get characters, the source will contain[1, 2, 3],args— gives access to query parameters. In case we call formovie, args will be containingidkey,context— an object that is shared between all resolvers within the query, it can contain an authentication token, adataSourcesobject which we will be passing as a parameter when creating the server,state— an advanced argument which contains information about the current query. The most interesting part is anASTpoint of the query the resolver was executed at.
Now, the other one, for characters:
./graphql.app/src/graphql/resolvers/character.js
export default {Character: {movies: async (source, args, { dataSources }, state) => {return dataSources.movieSource(source.movies);},},};
Here I would like to illustrate something. As I have already mentioned before, resolvers can get data from different sources, asynchronous or not.
So, let’s make those two data sources, for both movies and characters.
For the movies, the data source would be just a local array.
./graphql.app/src/graphql/dataSources/movie.js
const movies = [{id: '1',title: 'A New Hope',characters: [1, 2, 3, 4, 5],},{id: '2',title: 'The Empire Strikes Back',characters: [1, 2, 3],},{id: '3',title: 'Return of the Jedi',characters: [30, 31, 45],},];export default (ids) => {if (ids === null) {return movies;}return movies.filter((movie) => ids.indexOf(movie.id) >= 0);};
For characters, the data source is a little bit more complex, so it gets data from a remote source and process the result in order to make it suitable for us. We also use super-simple memoization technique there, just to make it work a little bit faster.
./graphql.app/src/graphql/dataSources/character.js
import axios from 'axios';// such kind of memoization is not good for production// use it like this only for demo purposes,// normally it is better to have something// like Redis hereconst cache = {};const extractId = (url) => {const found = url.match(/(\d+)\/$/);if (found.length) {return found[1];}return null;};export default async (ids) => {if (!ids || !ids.length) {return [];}const result = [];const missing = [];ids.forEach((id) => {// check what we already have in the cacheif (cache[id]) {result.push(cache[id]);} else {missing.push(id);}});if (missing.length) {// still having cache miss? request then!(await Promise.all(missing.map((id) =>axios.get(`https://swapi.co/api/people/${id}/`).catch(() => null)))).forEach((res) => {// process the result as it does not// have an appropriate formatif (res) {const data = res.data;const id = extractId(data.url);if (id) {const character = {id,fullName: data.name,movies: data.films.map((filmURL) => extractId(filmURL)),};// put to the cachecache[character.id] = character;// and to the resultresult.push(character);}}});}return result.filter((x) => !!x);};
It is time to modify our handler code. Edit the file ./graphql.app/src/index.js like the following:
import { ApolloServer } from 'apollo-server-lambda';import resolvers from './graphql/resolvers';import typeDefs from './graphql/types';import characterSource from './graphql/dataSources/character';import movieSource from './graphql/dataSources/movie';// creating the serverconst server = new ApolloServer({// passing types and resolvers to the servertypeDefs,resolvers,// initial context state, will be available in resolverscontext: () => ({}),// an object that goes to the "context" argument// when executing resolversdataSources: () => {return {characterSource,movieSource,};},});const handler = (event, context, callback) => {const handler = server.createHandler();// tell AWS lambda we do not want to wait for NodeJS event loop// to be empty in order to send the responsecontext.callbackWaitsForEmptyEventLoop = false;// process the requestreturn handler(event, context, callback);};export default handler;
You may have a question appeared though: “Hmm, but if this code is executed every time the function gets executed, isn’t it too much to start the ApolloServer on each hit?”. Answer: when you start your application and receive a very first hit, the lambda function executes all the code and moves from “cold” state to “warm”. If another hit comes within a range of several seconds, it causes execution of only the handler code, while all the object produced with the local, outer code remain the same. It dramatically improves performance.
All set, spinning up…
npx serverless offline start -r eu-central-1 --noTimeout --port 3000 --host 0.0.0.0
Hopefully, no error occurred, and our GraphQL Serverless endpoint is now online 🚀. We could also deploy this application into the wild, the process of how to do so is described in the previous article.
Apollo server offers a pretty web-interface to play nicely with different queries. To access the interface, just make a GET request to the endpoint:
http://localhost:3000/graphql
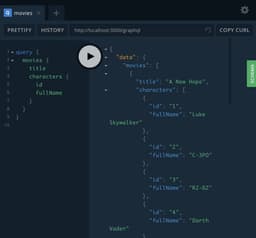
First, try to execute a quite complex query, like this one:
query {movies {titlecharacters {idfullName}}}
You will notice, that in the console a message "Executing Movie.characters resolver" appeared 3 times, once per each movie item. Now, if we try the following query:
query {movies {idtitle}}
/>
First, try to execute a quite complex query, like this one:
query {movies {titlecharacters {idfullName}}}
You will notice, that in the console a message “Executing Movie.characters resolver” appeared 3 times, once per each movie item. Now, if we try the following query:
query {movies {idtitle}}
We got no messages like that anymore because we have not requested “characters”. It means, that resolvers and therefore data sources get executed on-demand, and it definitely adds some flexibility to our code.
You may notice, that when declaring types, we have introduced a cyclic link: Movies → Characters → Movies → Characters →… So, we could also try to make a query like this, and technically it will work!
query {movies {titlecharacters {fullNamemovies {titlecharacters {fullNamemovies {title}}}}}}
How cool is that?
What we could also do is to send a parametrized query because we have declared it in our types:
query {movie(id: "1") {idtitlecharacters {fullName}}}
The parameter could be something more complex, than just a string. We could have created a query that accepts objects or arrays, this is useful to make a rich query that can do filtering or sorting based on different criteria.
Now we know how to set up an Apollo GraphQL server working on lambda and run it locally and in production. We barely scratched the surface of GraphQL world, but this is already a production-ready use-case and could be a nice start.
- here is the Proof-of-concept repository made for the article,
- read the official README for apollo-server-lambda
Thanks for reading! Hope this article was helpful for you. Happy GraphQL serving!
Next article: How to use DynamoDB with Apollo GraphQL and NodeJS Serverless →
← Previous article: How to use Serverless with Webpack and Docker locally and in production
