
Cronjobs on steroids with Temporal
Every backend engineer knows: background jobs are a pain to manage. No matter what they are: a concurrently running thread, a worker, or a kubernetes job, they all share the same traits: they are obscure, hard to track, and most importantly - noone knows what to do when they fail.
This is where Temporal comes into play.
Temporal is a platform for building and running background jobs with focus on reliability, resilience and visibility. People behind Temporal really knew the pain points, so they've built software that lets you run your code on your own servers, but under relentless supervision.
In a nutshell, you run your code inside your own process, but Temporal acts as a supervisor/orchestator, monitoring the progress of the job, tracking failures, doing retries and essentially seeing to this job being completed successfully (or die trying).
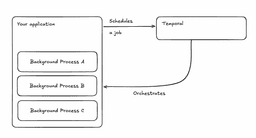
There are six main components of Temporal:
- Temporal server, which is by the way opensource and can be deployed on premises.
- Temporal worker, a piece of code that resides in your application and runs your code.
- Temporal client, used by your application to schedule/stop/resume/delete jobs. The client is also used by the worker to communicate with the orchestrator using gRPC.
- Temporal workflow, represents a scheduled job.
- Temporal activity, which is basically a re-enterable unit of work that is executed as part of the workflow.
- Optionally, a temporal UI where you can see how the jobs are doing through a pleasant UI.
And that's all we need to know about Temporal in order to start using it. Let's build a simple application that consists of two parts:
- An API app that can schedule a job.
- A worker app that actually executes jobs.
Sometimes these two apps are combined into a single app, making the worker co-located with the API app. But, that's usually not the way to go, because having two separate applications makes the system easier to scale and maintain.
I like Blender, I use it a lot for my 3D projects, I sometimes donate to Blender Foundation on different occasions. That is why this is essential for me to know how they are doing. I know, there is a public page where they post all the progress they made for the last month, but, for the sake of learning, why not have it done my way, by running a background job that does the same, but posts an update to... Slack?
The application will do the following: every day at 9:00 AM UTC it grabs a list of merged pull requests of a the Blender repository, refines them with AI and posts to a Slack channel.
The API service is a simple REST API that allows to schedule a job. It's written in Go and uses the Temporal client to communicate with the Temporal server.
The temporal client is shared between the API and the worker, as stated earlier, that's why the code is located in a common package.
package temporalimport ("context""log/slog""time""github.com/cenkalti/backoff/v4""go.temporal.io/sdk/client")func GetTemporalClient(ctx context.Context, log *slog.Logger, options client.Options) (client.Client, error) {// Add logger to optionsif log != nil {options.Logger = NewTemporalLogger(ctx, log)}var temporalClient client.Clientoperation := func() error {var err errortemporalClient, err = client.Dial(options)return err}// Configure exponential backoffbackoffStrategy := backoff.NewExponentialBackOff()backoffStrategy.MaxElapsedTime = 30 * time.SecondbackoffStrategy.InitialInterval = 1 * time.SecondbackoffStrategy.MaxInterval = 10 * time.Second// Retry with max 3 attemptserr := backoff.Retry(operation, backoff.WithMaxRetries(backoffStrategy, 3))return temporalClient, err}
Upon initializations it makes a simple dial to the Temporal server. Since the protocol is gRPC, the calls are unary, which means the persistent connection is not needed. The server may not be available immediately, that's why it is usually a good idea to wrap the dial with a retrier with an exponential backoff.
Note that the client is not instrumented with any observability tools.
It is usuall a good practice to wrap the client (the code you don't control) with a wrapper that you have power over, so you can get more freedom to instrument it with observability tools, change its behavior our add suppliementary features. This is why I've created a wrapping service for the client:
package temporalimport ("context""time"libtemporal "lib/temporal""github.com/pkg/errors""go.temporal.io/api/enums/v1""go.temporal.io/api/serviceerror""go.temporal.io/sdk/client")type Service struct {client client.Client}func NewService(client client.Client) *Service {return &Service{client: client}}func (s *Service) ExecuteWorkflow(ctx context.Context, workflowName string, workflowID string, workflowInput any, executeAt *time.Time) error {if s.client == nil {return errors.New("client is not initialized")}delay := time.Duration(0)if executeAt != nil {delay = time.Until(*executeAt)}options := client.StartWorkflowOptions{ID: workflowID,TaskQueue: libtemporal.DemoWorkflowsTaskQueue,WorkflowIDReusePolicy: enums.WORKFLOW_ID_REUSE_POLICY_TERMINATE_IF_RUNNING,StartDelay: delay,}_, err := s.client.ExecuteWorkflow(ctx, options, workflowName, workflowInput)if err != nil {return errors.Wrap(err, "failed to execute workflow")}return nil}func (s *Service) CancelWorkflow(ctx context.Context, workflowID string) error {if s.client == nil {return errors.New("client is not initialized")}err := s.client.CancelWorkflow(ctx, workflowID, "")if err != nil {var temporalErr *serviceerror.NotFoundif errors.As(err, &temporalErr) {// workflow didn't exist before, so we can safely ignore 404return nil}return errors.Wrap(err, "failed to cancel workflow")}return nil}
What is important here:
- The Temporal client does not allow starting workflows on a specific time, only delay it. To accommodate that, we made a dedicated wrapper that accepts the
executeAtparameter. - By default, the workflow id reuse policy is set to
TERMINATE_IF_RUNNING, which means that if the workflow with the same id is already running, it will be terminated before a new one is started. - The task queue is pre-defined. A system can have multiple task queues serving different purposes.
- If we are cancelling a non-existing workflow, we can safely ignore the
NotFounderror.
The application exposes one endpoint to start/stop a job (workflow):
POST http://localhost:2024/v1/workflows/githubContent-Type: application/json{"workflow_type": "GenerateReportGithubWorkflow","action": "start","parameters": {"repository": "blender/blender"}}
Here is how the service is eventually called inside the endpoint handler:
// ....func (h *WorkflowsHandler) ManageGithubWorkflow(ctx echo.Context) error {var request v1.GithubWorkflowRequestif err := ctx.Bind(&request); err != nil {return echo.NewHTTPError(http.StatusBadRequest, errors.Wrap(err, "failed to bind request"))}workflowID := h.createWorkflowID(request.Parameters.Repository)err := h.temporalService.ExecuteWorkflow(ctx.Request().Context(), string(request.WorkflowType), workflowID, request.Parameters, nil)if err != nil {return echo.NewHTTPError(http.StatusInternalServerError, errors.Wrap(err, "failed to execute workflow"))}return ctx.JSON(http.StatusOK, v1.GithubWorkflowResponse{WorkflowType: request.WorkflowType,WorkflowId: workflowID,Action: &request.Action,})}func (h *WorkflowsHandler) createWorkflowID(repository string) string {hash := sha256.Sum256([]byte(repository))return fmt.Sprintf("github-workflow-%x", hash[:6])}
Here is the main function of the API service. The client is initialized then in the main function, and must be closed during shutdown:
package mainimport ("api/internal/controller""api/internal/factory""api/internal/middleware""api/internal/service/config""api/internal/service/monitoring""context""fmt""io""log/slog""net/http"_ "net/http/pprof""os""github.com/labstack/echo/v4"echomiddleware "github.com/labstack/echo/v4/middleware""github.com/pkg/errors"workflowsV1Handlers "api/internal/controller/v1/workflows"workflowsV1 "api/internal/http/v1""lib/logger"libMiddleware "lib/middleware"libTemporal "lib/temporal""lib/util")func run(w io.Writer) error {ctx, cancel := context.WithCancel(context.Background())defer cancel()log := slog.New(slog.NewJSONHandler(w, nil))configService := config.NewConfigService()if err := configService.LoadConfig(); err != nil {return errors.Wrap(err, "could not load config")}e := echo.New()monitoringService := monitoring.NewService(configService)if err := monitoringService.Start(); err != nil {return errors.Wrap(err, "could not start monitoring service")}e.HTTPErrorHandler = libMiddleware.ErrorHandler(log)e.Use(libMiddleware.LoggerMiddleware(log))e.Use(middleware.ObservabilityMiddleware(monitoringService))e.Use(echomiddleware.CORSWithConfig(echomiddleware.CORSConfig{AllowOrigins: []string{"*"}, // todo: restrict to only the frontend domainAllowHeaders: []string{echo.HeaderOrigin, echo.HeaderContentType, echo.HeaderAccept},AllowMethods: []string{echo.GET, echo.POST, echo.PUT, echo.DELETE, echo.PATCH, echo.OPTIONS},}))// Register system endpointshealthHandler := controller.NewHealthHandler()e.GET("/health", healthHandler.Health)e.GET("/metrics", echo.WrapHandler(monitoringService.GetHandler()))// Register pprof endpoints// todo: remove for production// Open http://localhost:2024/debug/pprof/// To see the UI: go tool pprof -http=:8080 http://localhost:2024/debug/pprof/profilee.GET("/debug/pprof/*", echo.WrapHandler(http.DefaultServeMux))temporalClient, err := libTemporal.GetTemporalClient(ctx, log, configService.Config.Temporal.ToClientOptions())if err != nil {return errors.Wrap(err, "could not get temporal client")}depFactory := factory.NewFactory()depFactory.SetTemporalClient(temporalClient)// Register routesworkflowsHandler := workflowsV1Handlers.NewWorkflowsHandler(depFactory.GetTemporalService())workflowsV1.RegisterHandlers(e, workflowsHandler)return util.Run(ctx, nil, func(sigChan chan os.Signal) error {go func() {if err := e.Start(configService.Config.HTTP.Addr); err != nil {if errors.Is(err, http.ErrServerClosed) {// this is just a normal shutdown, so we can ignore itreturn}logger.Error(ctx, log, err.Error())sigChan <- nil // server couldn't start, exiting}}()logger.Info(ctx, log, "Application started")return nil}, func() {cancel()err := e.Shutdown(ctx)if err != nil {logger.Error(ctx, log, errors.Wrap(err, "could not shutdown echo server").Error())}monitoringService.Stop()temporalClient.Close()logger.Info(ctx, log, "Application stopped")})}func main() {err := run(os.Stdout)if err != nil {logger.Error(context.TODO(), slog.New(slog.NewJSONHandler(os.Stdout, nil)), fmt.Sprintf("could not start the application: %s", err.Error()))os.Exit(1)}}
The Run() function implements the graceful shutdown pattern. It listents to SIGTERM/SIGINT signals, the context cancellation and also an optional quitChan channel.
The select statement is obviously blocking.
When start() is unsuccessful, it tries to call stop() in best effort.
package utilimport ("context""os""os/signal""syscall""github.com/pkg/errors")func Run(ctx context.Context, quitChan <-chan struct{}, start func(chan os.Signal) error, stop func()) error {sigChan := make(chan os.Signal, 1)signal.Notify(sigChan, syscall.SIGTERM, syscall.SIGINT)if err := start(sigChan); err != nil {stop()return errors.Wrap(err, "could not start application")}select {case <-sigChan:stop()case <-quitChan:stop()case <-ctx.Done():stop()}return nil}
Now it's time to cover the worker part. It is a bit more tricky, because it contains the logic of workflows. It is important to know, that you can have as many instances of the worker as you want, and Temporal will make sure the jobs are distributed between them without any issues with concurrency.
The first thing we do is define the worker, just like we did it for the client:
package temporalimport ("context""errors""lib/logger"libTemporal "lib/temporal""log/slog""worker/internal/domain""worker/internal/interfaces""go.temporal.io/sdk/activity""go.temporal.io/sdk/client""go.temporal.io/sdk/interceptor""go.temporal.io/sdk/worker""go.temporal.io/sdk/workflow")func CreateWorker(ctx context.Context, client client.Client, log *slog.Logger, config *domain.Config, workflows []interfaces.TemporalWorkflowGroup, activities []interfaces.TemporalActivityGroup, quitCh chan<- struct{}) (func() error, func(), error) {if client == nil {return nil, nil, errors.New("client is not initialized")}w := worker.New(client, libTemporal.DemoWorkflowsTaskQueue, worker.Options{MaxConcurrentWorkflowTaskPollers: config.Temporal.Worker.MaxConcurrentWorkflowTaskPollers,MaxConcurrentWorkflowTaskExecutionSize: config.Temporal.Worker.MaxConcurrentWorkflowTaskExecutionSize,MaxConcurrentActivityTaskPollers: config.Temporal.Worker.MaxConcurrentActivityTaskPollers,MaxConcurrentActivityExecutionSize: config.Temporal.Worker.MaxConcurrentActivityExecutionSize,OnFatalError: func(err error) {logger.Error(ctx, log, "Worker fatal error", logger.F("error", err.Error()))quitCh <- struct{}{}},Interceptors: []interceptor.WorkerInterceptor{NewLoggingInterceptor(ctx, log),},})for _, wf := range workflows {for workflowName, workflowFunc := range wf.GetWorkflows() {w.RegisterWorkflowWithOptions(workflowFunc, workflow.RegisterOptions{Name: workflowName,})}}for _, act := range activities {for activityName, activityFunc := range act.GetActivities() {w.RegisterActivityWithOptions(activityFunc, activity.RegisterOptions{Name: activityName,})}}return func() error {logger.Info(ctx, log, "Worker started")return w.Start()}, w.Stop, nil}
Important to know:
- We worker needs a client too, because through it the worker polls Temporal for new jobs.
- There are two ways to start the worker: blocking via
Run(), and non-blocking viaStart(). I opted for the second option, because even though for this application the worker is a main feature (if it fails on start, the application may as well exit), I also need to take care of other things. - In order to play well with graceful shutdown, I've added the
OnFatalErrorcallback, that will send a signal to the shutdown channel, telling the serivce to stop. - The worker may take interceptors, they are essentially middlewares that can be used to alter the behavior of the worker. In my case, I log errors with the
LoggingInterceptor. - The worker takes certain settings instructing it how many concurrent tasks it can process. This is only one of the many ways to make it play well with the avaialbe resources. The other way is to use resource-based tuners, they will dynamically adjust the number of concurrent tasks based on the available CPU and memory.
- Every worker must be provided with a list of workflows and activities to process, let's talk about them next.
An activity is a function that is executed within the workflow. We have these activites defined:
package activitiesimport ("context""time""worker/internal/domain""worker/internal/interfaces""github.com/google/go-github/v62/github""github.com/samber/lo")type ReportActivityGroup struct {config *domain.ConfiggithubClient interfaces.GitHubClientopenaiClient interfaces.OpenAIClientslackClient interfaces.SlackClient}func NewReportActivityGroup(config *domain.Config, githubClient interfaces.GitHubClient, openaiClient interfaces.OpenAIClient, slackClient interfaces.SlackClient) interfaces.TemporalActivityGroup {return &ReportActivityGroup{config: config,githubClient: githubClient,openaiClient: openaiClient,slackClient: slackClient,}}func (a *ReportActivityGroup) GetRepositoryStatsActivity(ctx context.Context, input domain.GetRepositoryStatsActivityInput) (domain.GetRepositoryStatsActivityOutput, error) {commits, err := a.githubClient.FetchCommits(ctx, input.Repository)if err != nil {return domain.GetRepositoryStatsActivityOutput{}, err}commitItems := make([]domain.Commit, len(commits))for i, commit := range commits {comm := commit.Commitauthor := lo.FromPtrOr(comm.Author, github.CommitAuthor{})commitItems[i] = domain.Commit{SHA: lo.FromPtrOr(comm.SHA, ""),Message: lo.FromPtrOr(comm.Message, ""),AuthorName: lo.FromPtrOr(author.Name, ""),AuthorEmail: lo.FromPtrOr(author.Email, ""),Date: lo.FromPtrOr(author.Date, github.Timestamp{}).Format(time.RFC3339),}}return domain.GetRepositoryStatsActivityOutput{Commits: commitItems,}, nil}func (a *ReportActivityGroup) MakeHumanReadableSummaryActivity(ctx context.Context, input domain.MakeHumanReadableSummaryActivityInput) (domain.MakeHumanReadableSummaryActivityOutput, error) {summary, err := a.openaiClient.Complete(ctx,"You are a helpful assistant that summarizes text. The text is a list of commits from a repository. Return a summary of the commits in a human readable format and in markdown. Dont use ordered lists for formatting. Use emoji to make lists. Make it sound exciting! Don't mention every commit, just the most important ones. Conduct the generic yet precise summary. Menion the champion contributor(s) of this round.",input.Text,)if err != nil {return domain.MakeHumanReadableSummaryActivityOutput{}, err}return domain.MakeHumanReadableSummaryActivityOutput{Summary: summary,}, nil}func (a *ReportActivityGroup) PostToSlackActivity(ctx context.Context, input domain.PostToSlackActivityInput) (domain.PostToSlackActivityOutput, error) {err := a.slackClient.SendMessage(ctx, a.config.Slack.Channel, input.Summary)if err != nil {return domain.PostToSlackActivityOutput{}, err}return domain.PostToSlackActivityOutput{}, nil}func (a *ReportActivityGroup) GetActivities() map[string]any {schema := make(map[string]any)schema[domain.GetRepositoryStatsActivityName] = a.GetRepositoryStatsActivityschema[domain.MakeHumanReadableSummaryActivityName] = a.MakeHumanReadableSummaryActivityschema[domain.PostToSlackActivityName] = a.PostToSlackActivityreturn schema}
Here we have three activities: to get the commits, to make a human readable summary, and to post to Slack. I am not listing the code of the clients, because they are trivial to build.
Important to know:
- An activity can do anything, call any external system and product all kinds of side effects.
- An activity must be reenterable, ideally idempotent and atomic. If an activity makes changes in the database, it would be good if it had a transaction around it.
- You should not wrap every repository function with an activity, that unit of work would be too small. You should think of an activity as a unit of work that produce side effects and may fail and re-tried. So you need to keep that in mind when designing the activities.
Generally speaking a workflow is a pure function that is executed by the worker, potentially many times. Here is the workflow we have in the project:
package workflowsimport ("time""worker/internal/domain""worker/internal/interfaces""github.com/pkg/errors""go.temporal.io/sdk/temporal""go.temporal.io/sdk/workflow")type ReportWorkflowGroup struct {}func NewReportWorkflowGroup() interfaces.TemporalWorkflowGroup {return &ReportWorkflowGroup{}}func (w *ReportWorkflowGroup) GenerateReportGithubWorkflow(ctx workflow.Context, input domain.GenerateReportGithubWorkflowInput) error {var repoStats domain.GetRepositoryStatsActivityOutputerr := workflow.ExecuteActivity(w.withSafeguard(ctx, 10*time.Second, 5), domain.GetRepositoryStatsActivityName, domain.GetRepositoryStatsActivityInput{Repository: input.Repository,}).Get(ctx, &repoStats)if err != nil {return errors.Wrap(err, "failed to execute activity")}if len(repoStats.Commits) > 0 {var summary domain.MakeHumanReadableSummaryActivityOutputerr = workflow.ExecuteActivity(w.withSafeguard(ctx, 3*time.Minute, 3), domain.MakeHumanReadableSummaryActivityName, domain.MakeHumanReadableSummaryActivityInput{Text: repoStats.ToText(),}).Get(ctx, &summary)if err != nil {return errors.Wrap(err, "failed to execute activity")}var postToSlackOutput domain.PostToSlackActivityOutputerr = workflow.ExecuteActivity(w.withSafeguard(ctx, 10*time.Second, 5), domain.PostToSlackActivityName, domain.PostToSlackActivityInput{Repository: input.Repository,Summary: summary.Summary,}).Get(ctx, &postToSlackOutput)if err != nil {return errors.Wrap(err, "failed to execute activity")}}err = workflow.Sleep(ctx, w.getDurationToNext9AM(workflow.Now(ctx)))if err != nil {return errors.Wrap(err, "failed to sleep")}return workflow.NewContinueAsNewError(ctx, w.GenerateReportGithubWorkflow, input)}func (w *ReportWorkflowGroup) GetWorkflows() map[string]any {schema := make(map[string]any)schema[domain.GenerateReportGithubWorkflowName] = w.GenerateReportGithubWorkflowreturn schema}func (w *ReportWorkflowGroup) getDurationToNext9AM(now time.Time) time.Duration {next9AM := time.Date(now.Year(), now.Month(), now.Day(), 9, 0, 0, 0, now.Location())if now.Hour() >= 9 {next9AM = next9AM.Add(24 * time.Hour)}return next9AM.Sub(now)}func (w *ReportWorkflowGroup) withSafeguard(ctx workflow.Context, timeout time.Duration, attempts int32) workflow.Context {return workflow.WithActivityOptions(ctx, workflow.ActivityOptions{StartToCloseTimeout: timeout,RetryPolicy: &temporal.RetryPolicy{MaximumAttempts: attempts,},})}
Here are the most important things to know about workflows:
- Workflows must be pure functions, they should not have any side effects.
- Workflows call activities in order to perform actual work, communicate with other external systems, and stuff like that.
- A workflow cannot be paused, or Temporal will decide there is a deadlock and interrupt the execution at once. Even if you pause it with a debugger, it will be terminated.
- Inside a workflow, you don't have access to a regular golang context, you have to use
workflow.Contextinstead. - Due to point 3, you can't use any functions such as
time.Sleep()to suspend the execution. For that, you must useworkflow.Sleep(). - It is possible to create long running workflows, but you have to notify Temporal the workflow isn't stuck by periodically calling the
workflow.Heartbeat()function. - Workflows communicate with activities using Protocol Buffers, that's why values in input and output must be serializable.
- A workflow can be a recurring task, but just like with delayed scheduling, we must calculate the delay to the next execution, and sleep for that duration.
- In order to re-execute a workflow, we must use
workflow.NewContinueAsNewError(), which will restart the workflow from the beginning. This isn't a very clean pattern to control the execution through errors, but I guess Golang doesn't offer much of a choice due to its limitations.
Regarding calling the activities:
- Several activities will be executed in parallel if no
.Get()is called. - If
.Get()is used, the workflow awaits the activity to complete, making the activity call sequential. - Each activiy has its own timeout and retry policy, which is why we are using the
withSafeguardfunction to wrap the activity calls. By default there are no limits, so Temporal will not stop trying to execute the activity if it fails. We are giving theMakeHumanReadableSummaryActivityNamea little bit more time, because model inference is notoriously slow. - Activities can be called conditionally, these are not React hooks.
Here is how everything is put together in the main function. Note that we use dependency injection to pass the clients to activities instead of the worker. This creates a very clean testable codebase.
package mainimport ("context""fmt""io""log/slog""net/http"_ "net/http/pprof""os""worker/internal/github""worker/internal/interfaces""worker/internal/openai""worker/internal/service/config""worker/internal/service/monitoring""worker/internal/slack""worker/internal/temporal""worker/internal/temporal/activities""worker/internal/temporal/workflows""github.com/labstack/echo/v4""github.com/pkg/errors""lib/logger"libMiddleware "lib/middleware"libTemporal "lib/temporal""lib/util""worker/internal/controller")func run(w io.Writer) error {ctx, cancel := context.WithCancel(context.Background())defer cancel()log := slog.New(slog.NewJSONHandler(w, nil))configService := config.NewConfigService()if err := configService.LoadConfig(); err != nil {return errors.Wrap(err, "could not load config")}e := echo.New()monitoringService := monitoring.NewService(configService)if err := monitoringService.Start(); err != nil {return errors.Wrap(err, "could not start monitoring service")}e.HTTPErrorHandler = libMiddleware.ErrorHandler(log)// Register system endpointshealthHandler := controller.NewHealthHandler()e.GET("/health", healthHandler.Health)e.GET("/metrics", echo.WrapHandler(monitoringService.GetHandler()))// Register pprof endpoints// todo: remove for production// Open http://localhost:2024/debug/pprof/// To see the UI: go tool pprof -http=:8080 http://localhost:2024/debug/pprof/profilee.GET("/debug/pprof/*", echo.WrapHandler(http.DefaultServeMux))quitCh := make(chan struct{})temporalClient, err := libTemporal.GetTemporalClient(ctx, log, configService.Config.Temporal.ToClientOptions())if err != nil {return errors.Wrap(err, "could not get temporal client")}githubClient := github.NewClient(configService.GetConfig())githubClient.Connect(ctx)openaiClient := openai.NewClient(configService.GetConfig())slackClient := slack.NewClient(configService.GetConfig())startWorker, stopWorker, err := temporal.CreateWorker(ctx,temporalClient,log,configService.GetConfig(),[]interfaces.TemporalWorkflowGroup{workflows.NewReportWorkflowGroup(),},[]interfaces.TemporalActivityGroup{activities.NewReportActivityGroup(configService.GetConfig(), githubClient, openaiClient, slackClient),},quitCh,)return util.Run(ctx, quitCh, func(_ chan os.Signal) error {if err := startWorker(); err != nil {return errors.Wrap(err, "could not start temporal worker")}logger.Info(ctx, log, "Application started")return nil}, func() {cancel()stopWorker()err := e.Shutdown(ctx)if err != nil {logger.Error(ctx, log, errors.Wrap(err, "could not shutdown echo server").Error())}temporalClient.Close()monitoringService.Stop()logger.Info(ctx, log, "Application stopped")})}func main() {err := run(os.Stdout)if err != nil {logger.Error(context.TODO(), slog.New(slog.NewJSONHandler(os.Stdout, nil)), fmt.Sprintf("could not start the application: %s", err.Error()))os.Exit(1)}}
The external quitCh is passed to the Run() function to initiate the shutdown sequence if the worker fails to start.
Just a few words about the configuration files. I used to rely heavily on the environment variables before,
but for this project I've decided to evaluate the github.com/spf13/viper package. It can read from a yaml file in a predefined location, which is
especially convenient when the app is later deployed to a Kubernetes cluster: the configmaps can be materialized as yaml files and later
automatically picked up by the pod.
I also used github.com/go-playground/validator/v10 to validate the config, and github.com/creasty/defaults to set the default values from the struct tags.
These three packages combined form a very powerful tool for configuration management.
In order to run the application locally, I've created a docker compose file that starts the Temporal server, the API and the worker.
services:postgres:image: postgres:17container_name: temporal_postgresenvironment:POSTGRES_DB: temporalPOSTGRES_USER: adminPOSTGRES_PASSWORD: adminports:- '5432:5432'volumes:- ./.db:/var/lib/postgresql/datarestart: unless-stoppedhealthcheck:test: ['CMD-SHELL', 'pg_isready -U admin -d temporal']interval: 10stimeout: 5sretries: 5temporal:image: temporalio/auto-setup:latestcontainer_name: temporal_serverdepends_on:postgres:condition: service_healthyenvironment:- DB=postgres12_pgx- DB_PORT=5432- POSTGRES_USER=admin- POSTGRES_PWD=admin- POSTGRES_SEEDS=postgresports:- '7233:7233'restart: unless-stoppedtemporal-ui:image: temporalio/ui:latestcontainer_name: temporal_uidepends_on:- temporalenvironment:- TEMPORAL_ADDRESS=temporal:7233- TEMPORAL_CORS_ORIGINS=http://localhost:8080ports:- '8080:8080'restart: unless-stopped
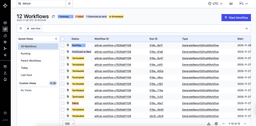
After calling the endpoint a bunch of times, I can see the workflows running in the Temporal UI:
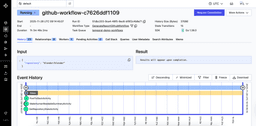
Here are the workflow details, note that the workflow is currently sleeping, waiting for 9:00 AM next day.
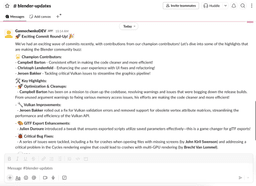
And here is the result in Slack:
That's it for today! We got ourselves a fully functional cloud native application suitable for deployment to a nearest Kubernetes cluster. The code is here, feel free to clone and play with it.
The list of potential applications of Temporal is endless. How about producing a digest of the latest news, refine it and post to a Telegram channel once a day? This is how automated news channels are managed today.
I hope you found this article useful. If you have any questions or feedback, please let me know.
