
Counters done right with a relational database
One lovely monday morning you are assigned to develop a list of task groups with counters: how many tasks are open, how many of them are completed, and so on.
"Well, nothing is easier than that, consider it done before lunch!" - you think, and roll your sleeves up...
The very first thing that comes to your mind is a really straightforward algorithm:
- On every task status change take it's
group_id, - Get all tasks of the group, iterate over it, make a
status => counthashmap:
startTransaction();// do your filthy stuff, update the task status...// poke the nose for a few milliseconds...// then update the countersconst tasks = query(`SELECT status FROM "tasks" WHERE group_id = ?;`, group_id);const statusCounts: Record<string, number> = {};tasks.forEach(({ status }) => {statusCounts[status] = status in statusCounts ? statusCounts[status] + 1 : 1;});// poke the nose for a few more milliseconds...
- Upsert the group updating the counters of the group.
query(`INSERT INTO "task_group" (group_id, open_task_count, completed_task_count)VALUES (?, ?, ?)ON CONFLICT DO UPDATE SET open_task_count = ?, completed_task_count = ?;`,group_id,statusCounts.open,statusCounts.completed,statusCounts.open,statusCounts.completed);commitTransaction();
And so you quickly develop it, test on you local machine, make sure that everything works. The PR gets approved and merged. You move the ticket to "Done", poure yourself a glass of chardonnay and watch the sun going down. Rainbows and unicorns all over the place.
Up until the very moment when your QA texts you in Slack that nothing f****ng works even on staging, the counters are completely off. The reality hits you like a wall.
You start digging, and suddenly realise, that...

Yeh, as you run your code in a transaction, on an even slightly loaded system concurrent transactions take place. When two pieces of code try to update the status of the same task, they obviously don't possess each other's data, so the result ends up being unpredictable.
"Fine!", say you, "I'll just move the counters update out of the transaction and that should do the trick!"
You make another PR, deploy and go to bed. Next morning...

Turns out, what you read from a connection to replica might not be exactly what is really there. This happens because the master-replica system is a distributed almost consistent system, so you clearly need to take this into consideration when designing your algorithms.
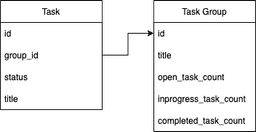
Unlike in the naive solution, this pattern assumes that we do not update anything, but just insert new records every time. Take a look at the entity diagram:

CREATE TABLE "task_group" (id char(36) PRIMARY KEY,title varchar(255) NOT NULL);CREATE TABLE "task_group_audit" (group_id char(36) NOT NULL,open_task_delta int NOT NULL,inprogress_task_delta int NOT NULL,completed_task_delta int NOT NULL);INSERT INTO "task_group" (id, title) VALUES ('b6e8d4dc-68d9-11ed-9022-0242ac120002', 'My group');
Let's say a new task emerges. It must have the "open" status by default, and we need to log it. That is, we add a new entry to the audit table:
INSERT INTO "task_group_audit" (group_id, open_task_delta, inprogress_task_delta, completed_task_delta)VALUES ('b6e8d4dc-68d9-11ed-9022-0242ac120002', 1, 0, 0);
Then, as the task goes to "in progress", we log this event as well, indicating that the amount of "open" tasks also decreased:
INSERT INTO "task_group_audit" (group_id, open_task_delta, inprogress_task_delta, completed_task_delta)VALUES ('b6e8d4dc-68d9-11ed-9022-0242ac120002', -1, 1, 0);
Finally, when the task goes to "completed", we record this:
INSERT INTO "task_group_audit" (group_id, open_task_delta, inprogress_task_delta, completed_task_delta)VALUES ('b6e8d4dc-68d9-11ed-9022-0242ac120002', 0, -1, 1);
Then, when getting the list of groups, we do grouping and aggregation:
SELECTgroup_id,task_group.title,SUM(open_task_delta) as open_task_count,SUM(inprogress_task_delta) as inprogress_task_count,SUM(completed_task_delta) as completed_task_countFROM"task_group_audit"INNER JOIN "task_group"ONtask_group_audit.group_id = task_group.idGROUP BYgroup_id, task_group.title;
This method does not have flaws of that naive solution, because the order of operations does not matter, read replica is not used, since we don't read anything, and the counter indications will be eventually consistent as soon as every transaction is committed.
However, nothing is perfect, and this method has flaws and limitations as well.
- The lifecycle of the entity must be rather short. The "task" entity is a good example, since it only has that few states. On the contrary, if we need to count things such as channels in a messenger, then the data could potentially grow indefinitely.
- If all of a sudden a need for sorting or filtering by the counter values emerges, the solution may quickly degrade into a massive performance bottleneck.
- The system must not allow execution of the same action on the same task multiple times, because the action will be logged multiple times as well, distorting the counters. This can happen, for example, when two managers work with the same task simultaneously.
- Materialised views. You can potentially have a view, and update it on a trigger, but the logic behind the counters should be simple enough for the database to calculate.
- A dedicated microservice. One of the most flexible solution is to have a microservice dedicated to one and only purpose: listen to a queue/pubsub and for every incoming element re-calculate the counters based on whatever logic. Among the downsides: extra maintenance cost and not always consistent indications.
Well, as you clearly see, making counters is actually not a piece of cake when it comes to a distributed, almost consistent system with concurrent transactions. Hope this article was helpful by uncovering some of the underwater rocks of such a seemingly straightforward topic.
